本文主要受 STIR 论文 作者的博客文章 STIR: Reed–Solomon Proximity Testing with Fewer Queries 与演讲 ZK11: STIR: Reed–Solomon Proximity Testing with Fewer Queries - Gal Arnon & Giacomo Fenzi 的启发,介绍 STIR 协议。
STIR 和 FRI 一样,也是解决 Reed-Solomon Proximity Testing 问题,不过与 FRI 相比,其有更低的查询复杂度,这会降低 argument 的大小与 Verifier 的哈希复杂度。那么 STIR 是如何实现这一点的呢?其实谜底就在谜面上,STIR 取了 S hift T o I mprove R ate 的首字母,STIR 的核心点就在其通过每次移动 evaluation domain,来提升码率。直观地理解,码率实际刻画的是码字中所含的真实信息的比例,码率降低,真实信息减少,对应码字中的冗余就增大了,Verifier 就更容易测试接受到的一个消息到该编码空间的 proximity 了,其测试能力变得更强了。换句话说,由于 Verifier 的测试能力变强,那么其只需要更少的查询次数就能达到目标的安全性了。下面通过对比 FRI 和 STIR,来看看 STIR 是如何降低码率的。
FRI v.s. STIR ¶ 对于一个有限域 F \mathbb{F} F L ⊆ F \mathcal{L} \subseteq \mathbb{F} L ⊆ F ∣ L ∣ = n |\mathcal{L}| = n ∣ L ∣ = n d d d n n n d d d R S [ F , L , d ] \mathrm{RS}[\mathbb{F},\mathcal{L},d] RS [ F , L , d ] f : L → F f: \mathcal{L} \rightarrow \mathbb{F} f : L → F f f f d d d L \mathcal{L} L ρ : = d / ∣ L ∣ \rho := d/|\mathcal{L}| ρ := d /∣ L ∣
协议的目标是解决 Reed-Solomon Proximity Testing 问题,其中 Verifier 是可以通过查询获得一个函数 f : L → F f: \mathcal{L} \rightarrow \mathbb{F} f : L → F f f f f f f
f f f f ∈ R S [ F , L , d ] f \in \mathrm{RS}[\mathbb{F},\mathcal{L},d] f ∈ RS [ F , L , d ] f f f R S [ F , L , d ] \mathrm{RS}[\mathbb{F},\mathcal{L},d] RS [ F , L , d ] δ \delta δ Δ ( f , R S [ F , L , d ] ) > δ \Delta(f, \mathrm{RS}[\mathbb{F},\mathcal{L},d]) > \delta Δ ( f , RS [ F , L , d ]) > δ 我们在 IOPP(Interactive Oracle Proofs of Proximity) 模型下考虑上述 Reed-Solomon Proximity Testing 问题,此时 Verifier 可以和 Prover 进行交互,并且能通过 oracle 获得 Prover 的消息,如下图所示。
Verifier 通过与 Prover 一系列交互之后,分两种情况:
f ∈ R S [ F , L , d ] f \in \mathrm{RS}[\mathbb{F},\mathcal{L},d] f ∈ RS [ F , L , d ] Δ ( f , R S [ F , L , d ] ) > δ \Delta(f, \mathrm{RS}[\mathbb{F},\mathcal{L},d]) > \delta Δ ( f , RS [ F , L , d ]) > δ 我们在 k k k
在 FRI 协议中,假设 g 1 g_1 g 1 α 1 \alpha_1 α 1 k k k L k = { x k , x ∈ L } \mathcal{L}^{k} = \{x^k,x\in \mathcal{L}\} L k = { x k , x ∈ L } f ∈ R S [ F , L , d ] f \in \mathrm{RS}[\mathbb{F},\mathcal{L},d] f ∈ RS [ F , L , d ] g 1 ∈ R S [ F , L k , d / k ] g_1 \in \mathrm{RS}[\mathbb{F},\mathcal{L}^k,d/k] g 1 ∈ RS [ F , L k , d / k ] g i ∈ R S [ F , L k i , d / k i ] g_i \in \mathrm{RS}[\mathbb{F},\mathcal{L}^{k^i},d/k^i] g i ∈ RS [ F , L k i , d / k i ] i i i
ρ i = d k i ∣ L i ∣ = d k i ⋅ k i n = d n = ρ \rho_i = \frac{\frac{d}{k^i}}{|\mathcal{L}_i|} = \frac{d}{k^i} \cdot \frac{k^i}{n} = \frac{d}{n} = \rho ρ i = ∣ L i ∣ k i d = k i d ⋅ n k i = n d = ρ 可以发现在每一轮中,码率 ρ i \rho_i ρ i ρ \rho ρ
而在 STIR 协议中,注意 g 1 ′ g_1' g 1 ′ k k k L ′ \mathcal{L}' L ′ k k k f ∈ R S [ F , L , d ] f \in \mathrm{RS}[\mathbb{F},\mathcal{L},d] f ∈ RS [ F , L , d ] g 1 ′ ∈ R S [ F , L ′ , d / k ] g_1' \in \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k] g 1 ′ ∈ RS [ F , L ′ , d / k ] i i i g i ′ ∈ R S [ F , L i ′ , d / k i ] g_i' \in \mathrm{RS}[\mathbb{F},\mathcal{L}_{i}',d/k^i] g i ′ ∈ RS [ F , L i ′ , d / k i ]
ρ i = d k i ∣ L i ′ ∣ = d k i ⋅ 2 i n = ( 2 k ) i ⋅ d n = ( 2 k ) i ⋅ ρ \rho_i = \frac{\frac{d}{k^i}}{|\mathcal{L}'_i|} = \frac{d}{k^i} \cdot \frac{2^i}{n} = \left( \frac{2}{k}\right)^i \cdot \frac{d}{n} = \left( \frac{2}{k}\right)^i \cdot \rho ρ i = ∣ L i ′ ∣ k i d = k i d ⋅ n 2 i = ( k 2 ) i ⋅ n d = ( k 2 ) i ⋅ ρ 如果 2 k < 1 \frac{2}{k} < 1 k 2 < 1 k > 2 k > 2 k > 2 ρ i \rho_{i} ρ i
当我们将上述的 IOPP 编译成 SNARK 时,需要用到 BCS 转换 ([BCS16], BCS transformation) ,分为两步:
将 Prover 的消息进行 Merkle 承诺,当 Verifier 想要查询时就打开这些承诺,这一步将 IOPP 转换为了一个简洁的交互论证(succinct interactive argument) 。 使用 Fait-Shamir 转换将第一步得到的简洁的交互论证转换为非交互的。 在BCS转换中,就需要 IOPP 有一个比较强的 soundness 性质,称为 round-by-round soundness,意思是要求 IOPP 在每一轮有比较小的 soundness error,这比要求整个 IOPP 有比较小的 soundness error 要求更强。我们假设要求 round-by-round soundness error 的界为 2 − λ 2^{-\lambda} 2 − λ t i t_{i} t i M M M ∑ i = 0 M t i \sum_{i = 0}^M t_i ∑ i = 0 M t i δ \delta δ δ = 1 − ρ \delta = 1 - \sqrt{\rho} δ = 1 − ρ
FRI 的查询复杂度为:
O ( λ ⋅ log d − log ρ ) O \left( \lambda \cdot \frac{\log d}{- \log \sqrt{\rho}} \right) O ( λ ⋅ − log ρ log d ) STIR 的查询复杂度为:
O ( λ ⋅ log ( log d − log ρ ) + log d ) O \left( \lambda \cdot \log \left( \frac{\log d}{- \log \sqrt{\rho}} \right) + \log d \right) O ( λ ⋅ log ( − log ρ log d ) + log d ) 在 STIR 查询复杂度中,d d d λ ⋅ log ( log d − log ρ ) \lambda \cdot \log \left( \frac{\log d}{- \log \sqrt{\rho}} \right) λ ⋅ log ( − l o g ρ l o g d ) log log \log \log log log log \log log
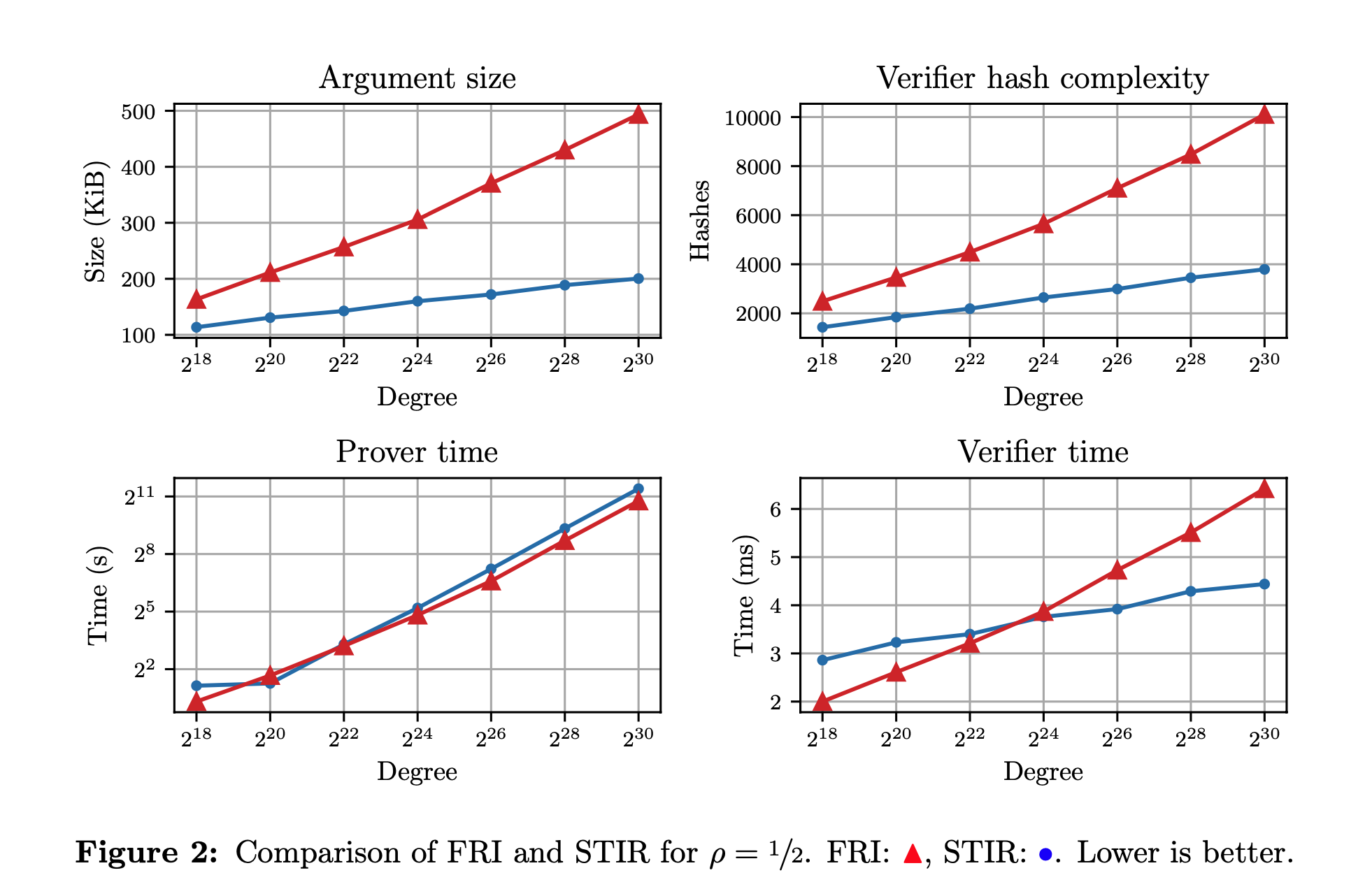
在论文 [ACFY24] 6.4 节中的图 2 给出了 FRI 和 STIR 的对比试验结果,可以发现 STIR 降低查询复杂度导致了其在 argument 大小和 Verifier 计算的哈希数量相比 FRI 更优。这也比较好理解,更少的查询复杂度意味着:
减少整个 argument 大小是显然的。 由于查询次数更少,那么 Verifier 需要打开的 Merkle 承诺就更少,计算对应的哈希数量就更少。 关于 RS 编码的强有力的工具 ¶ 在这里先引入几个关于 RS 编码的强大工具,其能帮助我们理解具体的 STIR 协议构造。
Folding ¶ 对于一个函数 f : L → F f: \mathcal{L} \rightarrow \mathbb{F} f : L → F r ∈ F r \in \mathbb{F} r ∈ F k k k f r : = F o l d ( f , r ) : L k → F f_r := \mathrm{Fold}(f,r) : \mathcal{L}^{k} \rightarrow \mathbb{F} f r := Fold ( f , r ) : L k → F x ∈ L k x \in \mathcal{L}^{k} x ∈ L k L \mathcal{L} L k k k y y y y k = x y^k = x y k = x k k k ( y , f ( y ) ) (y, f(y)) ( y , f ( y )) k k k p ^ \hat{p} p ^ p ^ ( y ) = f ( y ) \hat{p}(y) = f(y) p ^ ( y ) = f ( y ) p ^ ( r ) \hat{p}(r) p ^ ( r ) f r ( x ) f_r(x) f r ( x )
第一个性质是距离的保持。
如果折叠前的函数 f ∈ R S [ F , L , d ] f \in \mathrm{RS}[\mathbb{F}, \mathcal{L}, d] f ∈ RS [ F , L , d ] r ∈ F r \in \mathbb{F} r ∈ F f r ∈ R S [ F , L k , d / k ] f_r \in \mathrm{RS}[\mathbb{F}, \mathcal{L}^k, d/k] f r ∈ RS [ F , L k , d / k ] 对于 δ ∈ ( 0 , 1 − ρ ) \delta \in (0, 1 - \sqrt{\rho}) δ ∈ ( 0 , 1 − ρ ) f f f R S [ F , L , d ] \mathrm{RS}[\mathbb{F}, \mathcal{L}, d] RS [ F , L , d ] δ \delta δ 1 − p o l y ( ∣ L ∣ ) / F 1 - \mathrm{poly}(|\mathcal{L}|)/\mathbb{F} 1 − poly ( ∣ L ∣ ) / F r r r f r f_r f r R S [ F , L k , d / k ] \mathrm{RS}[\mathbb{F}, \mathcal{L}^k, d/k] RS [ F , L k , d / k ] δ \delta δ 这个性质保证了我们可以大胆进行折叠,如果 Prover 作弊,提供了距离编码空间有 δ \delta δ δ \delta δ
第二个性质称为 Local,意思是如果要得到折叠后的函数在任意一点的值,只需要查询 f f f k k k k k k p ^ \hat{p} p ^ r r r p ^ ( r ) \hat{p}(r) p ^ ( r ) F o l d ( f , r ) \mathrm{Fold}(f,r) Fold ( f , r ) f f f
Quotienting ¶ 对于函数 f : L → F f: \mathcal{L} \rightarrow \mathbb{F} f : L → F p : S → F p: S \rightarrow \mathbb{F} p : S → F S ⊆ F S \subseteq \mathbb{F} S ⊆ F f f f
Q u o t i e n t ( f , S , p ) ( x ) : = f ( x ) − p ^ ( x ) ∏ a ∈ S ( X − a ) , \mathrm{Quotient}(f, S, p)(x) := \frac{f(x) - \hat{p}(x)}{\prod_{a \in S}(X - a)}, Quotient ( f , S , p ) ( x ) := ∏ a ∈ S ( X − a ) f ( x ) − p ^ ( x ) , 其中 p ^ \hat{p} p ^ a ∈ S a \in S a ∈ S p ^ ( a ) = p ( a ) \hat{p}(a) = p(a) p ^ ( a ) = p ( a ) ∣ S ∣ |S| ∣ S ∣
该函数的一个重要性质是一致性(Consistency) ,假设 S S S L \mathcal{L} L
如果 f ∈ R S [ F , L , d ] f \in \mathrm{RS}[\mathbb{F}, \mathcal{L}, d] f ∈ RS [ F , L , d ] d d d L \mathcal{L} L S S S p p p Q u o t i e n t ( f , S , p ) ∈ R S [ F , L , d − ∣ S ∣ ] \mathrm{Quotient}(f, S, p) \in \mathrm{RS}[\mathbb{F}, \mathcal{L}, d - |S|] Quotient ( f , S , p ) ∈ RS [ F , L , d − ∣ S ∣ ] 如果对于任意一个离 f f f δ \delta δ d d d u ^ \hat{u} u ^ u ^ \hat{u} u ^ p p p S S S a ∈ S a \in S a ∈ S u ^ ( a ) ≠ p ( a ) \hat{u}(a) \neq p(a) u ^ ( a ) = p ( a ) Q u o t i e n t ( f , S , p ) \mathrm{Quotient}(f, S, p) Quotient ( f , S , p ) R S [ F , L , d − ∣ S ∣ ] \mathrm{RS}[\mathbb{F}, \mathcal{L}, d - |S|] RS [ F , L , d − ∣ S ∣ ] δ \delta δ 对于上述第 2 点,在 f f f δ \delta δ u ^ \hat{u} u ^ L i s t ( f , d , δ ) \mathrm{List}(f,d,\delta) List ( f , d , δ ) u ^ ∈ L i s t ( f , d , δ ) \hat{u} \in \mathrm{List}(f,d,\delta) u ^ ∈ List ( f , d , δ ) S S S u ^ ( a ) ≠ p ( a ) \hat{u}(a) \neq p(a) u ^ ( a ) = p ( a ) Q u o t i e n t ( f , S , p ) \mathrm{Quotient}(f, S, p) Quotient ( f , S , p ) δ \delta δ f ( a ) − p ( a ) f(a) - p(a) f ( a ) − p ( a )
注意到这里要求任意的 u ^ ∈ L i s t ( f , d , δ ) \hat{u} \in \mathrm{List}(f,d,\delta) u ^ ∈ List ( f , d , δ ) u ^ \hat{u} u ^ p p p S S S f f f δ \delta δ
Q u o t i e n t \mathrm{Quotient} Quotient f f f f f f a a a b b b Q u o t i e n t ( f , { a } , p ) \mathrm{Quotient}(f, \{a\}, p) Quotient ( f , { a } , p ) p ( a ) = b p(a) = b p ( a ) = b
Q u o t i e n t ( f , { a } , p ) = f ( x ) − p ( x ) x − a \mathrm{Quotient}(f, \{a\}, p) = \frac{f(x) - p(x)}{x - a} Quotient ( f , { a } , p ) = x − a f ( x ) − p ( x ) 接着证明 Q u o t i e n t ( f , { a } , p ) ∈ R S [ F , L , d − 1 ] \mathrm{Quotient}(f, \{a\}, p) \in \mathrm{RS}[\mathbb{F}, \mathcal{L}, d - 1] Quotient ( f , { a } , p ) ∈ RS [ F , L , d − 1 ] f f f a a a b b b f ( a ) ≠ b f(a) \neq b f ( a ) = b f ( a ) ≠ p ( a ) f(a) \neq p(a) f ( a ) = p ( a ) Q u o t i e n t ( f , { a } , p ) \mathrm{Quotient}(f, \{a\}, p) Quotient ( f , { a } , p ) R S [ F , L , d − 1 ] \mathrm{RS}[\mathbb{F}, \mathcal{L}, d - 1] RS [ F , L , d − 1 ] δ \delta δ f f f f f f Q u o t i e n t \mathrm{Quotient} Quotient δ \delta δ
Q u o t i e n t \mathrm{Quotient} Quotient Q u o t i e n t \mathrm{Quotient} Quotient x ∈ L \ S x \in \mathcal{L}\backslash\mathcal{S} x ∈ L \ S f f f x x x
Out of Domain Sampling ¶ Out of Domain Sampling 是一种强大的工具,其可以帮助我们限制 Prover 提供的函数 f f f δ \delta δ
对于函数 f : L → F f: \mathcal{L} \rightarrow \mathbb{F} f : L → F L \mathcal{L} L α ∈ F \ L \alpha \in \mathbb{F} \backslash \mathcal{L} α ∈ F \ L β \beta β f f f δ \delta δ L i s t ( f , d , δ ) \mathrm{List}(f,d,\delta) List ( f , d , δ ) u ^ \hat{u} u ^ u ^ ( α ) = β \hat{u}(\alpha) = \beta u ^ ( α ) = β
可以用代数基本定理来说明这一点。我们只要证明在 L i s t ( f , d , δ ) \mathrm{List}(f,d,\delta) List ( f , d , δ ) u ^ ′ \hat{u}' u ^ ′ u ^ \hat{u} u ^ α \alpha α u ^ ( α ) = β \hat{u}(\alpha) = \beta u ^ ( α ) = β
先固定两个不同的码字 u ^ ′ \hat{u}' u ^ ′ u ^ \hat{u} u ^ d d d
Pr α ← F \ L [ u ^ ′ ( α ) = u ^ ( α ) ] ≤ d − 1 ∣ F ∣ − ∣ L ∣ \Pr_{\alpha \leftarrow \mathbb{F} \backslash \mathcal{L}} [\hat{u}'(\alpha) = \hat{u}(\alpha)] \le \frac{d - 1}{|\mathbb{F}| - |\mathcal{L}|} α ← F \ L Pr [ u ^ ′ ( α ) = u ^ ( α )] ≤ ∣ F ∣ − ∣ L ∣ d − 1 假设 R S [ F , L , d ] \mathrm{RS}[\mathbb{F}, \mathcal{L},d] RS [ F , L , d ] ( δ , l ) (\delta, l) ( δ , l ) δ \delta δ l l l u ^ ′ \hat{u}' u ^ ′ u ^ \hat{u} u ^ ( l 2 ) \binom{l}{2} ( 2 l ) u ^ ′ \hat{u}' u ^ ′ u ^ \hat{u} u ^ α \alpha α ( l 2 ) ⋅ d − 1 ∣ F ∣ − ∣ L ∣ \binom{l}{2} \cdot \frac{d - 1}{|\mathbb{F}| - |\mathcal{L}|} ( 2 l ) ⋅ ∣ F ∣ − ∣ L ∣ d − 1
如何去限制 Prover 发送过来的 β \beta β f f f a a a
深入 STIR 协议的一次迭代 ¶ 在这一节中将应用前面提到的三个工具,深入 STIR 协议中的一次迭代。
目标:
初始给定一个函数 f f f R S [ F , L , d ] \mathrm{RS}[\mathbb{F},\mathcal{L},d] RS [ F , L , d ] L = ⟨ ω ⟩ \mathcal{L} =\langle \omega \rangle L = ⟨ ω ⟩ 经过一次迭代后,证明函数 f ′ ∈ R S [ F , L ′ , d / k ] f' \in \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k] f ′ ∈ RS [ F , L ′ , d / k ] L ′ = ω ⋅ ⟨ ω 2 ⟩ \mathcal{L}' = \omega \cdot \langle \omega^2 \rangle L ′ = ω ⋅ ⟨ ω 2 ⟩ 也就是函数 f f f k k k d / k d/k d / k f ′ f' f ′ L ′ \mathcal{L}' L ′ k k k
关于 evaluation domain L = ⟨ ω ⟩ \mathcal{L} =\langle \omega \rangle L = ⟨ ω ⟩ L ′ = ω ⋅ ⟨ ω 2 ⟩ \mathcal{L}' = \omega \cdot \langle \omega^2 \rangle L ′ = ω ⋅ ⟨ ω 2 ⟩ ω 8 = 1 \omega^8 = 1 ω 8 = 1
这样构造的 L ′ \mathcal{L}' L ′ L \mathcal{L} L ⟨ ω 2 ⟩ \langle \omega^2 \rangle ⟨ ω 2 ⟩ L ′ = ⟨ ω 2 ⟩ \mathcal{L}' = \langle \omega^2 \rangle L ′ = ⟨ ω 2 ⟩ k = 4 k = 4 k = 4 L 4 = { ω 4 , ω 8 } \mathcal{L}^4 = \{\omega^4, \omega^8\} L 4 = { ω 4 , ω 8 } L ′ = { ω 1 , ω 3 , ω 5 , ω 7 } \mathcal{L}' = \{\omega^1, \omega^3,\omega^5, \omega^7\} L ′ = { ω 1 , ω 3 , ω 5 , ω 7 } L 4 ∩ L ′ \mathcal{L}^4 \cap \mathcal{L}' L 4 ∩ L ′ F i l l \mathrm{Fill} Fill F i l l \mathrm{Fill} Fill
一次迭代的协议流程如下图所示:
取样折叠随机数(Sample folding randomness): Verifier 先从 F \mathbb{F} F r f o l d r^{\mathrm{fold}} r fold f f f 发送折叠函数(Send folded function): Prover 发送折叠后的函数 g : L ′ → F g: \mathcal{L}' \rightarrow \mathbb{F} g : L ′ → F g g g g ^ \hat{g} g ^ L ′ \mathcal{L}' L ′ g g g g ^ \hat{g} g ^ L ′ \mathcal{L}' L ′ g ^ \hat{g} g ^ F o l d ( f , r f o l d ) \mathrm{Fold}(f, r^{\mathrm{fold}}) Fold ( f , r fold ) r f o l d r^{\mathrm{fold}} r fold f f f k k k F o l d ( f , r f o l d ) : L k → F \mathrm{Fold}(f, r^{\mathrm{fold}}) : \mathcal{L}^k \rightarrow \mathbb{F} Fold ( f , r fold ) : L k → F L k \mathcal{L}^k L k L ′ \mathcal{L}' L ′ F o l d ( f , r f o l d ) \mathrm{Fold}(f, r^{\mathrm{fold}}) Fold ( f , r fold ) L ′ \mathcal{L}' L ′ g ^ : L ′ → F \hat{g}: \mathcal{L}' \rightarrow \mathbb{F} g ^ : L ′ → F d / k d/k d / k Out-of-domain sample: Verifier 从 F \ L ′ \mathbb{F}\backslash \mathcal{L}' F \ L ′ r o u t r^{\mathrm{out}} r out Out-of-domain reply: Prover 答复 β ∈ F \beta \in \mathbb{F} β ∈ F β : = g ^ ( r o u t ) \beta := \hat{g}(r^{\mathrm{out}}) β := g ^ ( r out ) 📝 Notes
这里第 3 步和第 4 步的目的是为了用 Out of domain Sampling 来将 g ′ g' g ′ δ \delta δ
Shift queries: Verifier 从 ⟨ ω k ⟩ \langle \omega^k \rangle ⟨ ω k ⟩ t t t ∀ i ∈ [ t ] , r i s h i f t ← ⟨ ω k ⟩ \forall i \in [t],r_i^{\mathrm{shift}} \leftarrow \langle \omega^k \rangle ∀ i ∈ [ t ] , r i shift ← ⟨ ω k ⟩ f f f y i : = f f o l d ( r i s h i f t ) y_i := f_{\mathrm{fold}}(r_i^{\mathrm{shift}}) y i := f fold ( r i shift ) f f o l d : = F o l d ( f , r f o l d ) f_{\mathrm{fold}} :=\mathrm{Fold}(f, r^{\mathrm{fold}}) f fold := Fold ( f , r fold ) 在第 2 步中 Prover 发送了 g : L ′ → F g: \mathcal{L}' \rightarrow \mathbb{F} g : L ′ → F F o l d ( f , r f o l d ) \mathrm{Fold}(f, r^{\mathrm{fold}}) Fold ( f , r fold ) L ′ \mathcal{L}' L ′ L ′ \mathcal{L}' L ′ f f f F o l d ( f , r f o l d ) \mathrm{Fold}(f, r^{\mathrm{fold}}) Fold ( f , r fold ) L k \mathcal{L}^k L k
在第 3 步和第 4 步先用 Out-of-domain Sampling 的方法限制 g g g δ \delta δ u ^ \hat{u} u ^ F o l d ( f , r f o l d ) \mathrm{Fold}(f, r^{\mathrm{fold}}) Fold ( f , r fold ) L k \mathcal{L}^k L k u ^ \hat{u} u ^ L k \mathcal{L}^k L k
将所有这些要确保一致性的点组成集合 G : = { r o u t , r 1 s h i f t , … , r t s h i f t } \mathcal{G} := \{r^{\mathrm{out}},r_1^{\mathrm{shift}}, \ldots, r_t^{\mathrm{shift}}\} G := { r out , r 1 shift , … , r t shift } p : G → F p: \mathcal{G}\rightarrow \mathbb{F} p : G → F
p ( r o u t ) = β , p(r^{\mathrm{out}}) = \beta, p ( r out ) = β , p ( r i s h i f t ) = y i . p(r_i^{\mathrm{shift}}) = y_i. p ( r i shift ) = y i . 定义下一步的函数 f ′ f' f ′
f ′ : = Q u o t i e n t ( f , G , p ) = g ( x ) − p ^ ( x ) ∏ a ∈ G ( X − a ) . f' := \mathrm{Quotient}(f, \mathcal{G}, p) = \frac{g(x) - \hat{p}(x)}{\prod_{a \in \mathcal{G}}(X - a)}. f ′ := Quotient ( f , G , p ) = ∏ a ∈ G ( X − a ) g ( x ) − p ^ ( x ) . 由于 Quotient 函数具有 Local 性质,因此想要计算 f ′ f' f ′ L ′ \mathcal{L}' L ′ g g g L ′ \mathcal{L}' L ′
至此,接下来测试 f ′ f' f ′ R S [ F , L ′ , d / k ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k] RS [ F , L ′ , d / k ] δ \delta δ
细看 f ′ f' f ′ f ′ ∈ R S [ F , L ′ , d / k − ∣ G ∣ ] f' \in \mathrm{RS}[\mathbb{F}, \mathcal{L}', d/k - |\mathcal{G}|] f ′ ∈ RS [ F , L ′ , d / k − ∣ G ∣ ] f ′ f' f ′ d / k d/k d / k
Soundness 分析 ¶ 在本小节将对一次迭代进行 soundness 分析,即如果 Prover 作弊, f f f R S [ F , L , d ] \mathrm{RS}[\mathbb{F},\mathcal{L},d] RS [ F , L , d ] δ \delta δ f ′ f' f ′ R S [ F , L ′ , d / k − ∣ G ∣ ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k- |\mathcal{G}|] RS [ F , L ′ , d / k − ∣ G ∣ ]
命题 1 [ACFY24, Lemma 1] 如果 f f f R S [ F , L , d ] \mathrm{RS}[\mathbb{F},\mathcal{L},d] RS [ F , L , d ] δ \delta δ ( 1 − δ ) t + p o l y ( ∣ L ∣ ) / ∣ F ∣ (1 - \delta)^t + \mathrm{poly}(|\mathcal{L}|)/|\mathbb{F}| ( 1 − δ ) t + poly ( ∣ L ∣ ) /∣ F ∣ f ′ f' f ′ R S [ F , L ′ , d / k − ∣ G ∣ ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k- |\mathcal{G}|] RS [ F , L ′ , d / k − ∣ G ∣ ] ( 1 − ρ ′ ) (1 - \sqrt{\rho'}) ( 1 − ρ ′ )
证明思路:
根据折叠函数保持距离的性质,对 f f f r f o l d r^{\mathrm{fold}} r fold f r f o l d : = F o l d ( f , r f o l d ) f_{r^{\mathrm{fold}}} := \mathrm{Fold}(f, r^{\mathrm{fold}}) f r fold := Fold ( f , r fold ) R S [ F , L k , d / k ] \mathrm{RS}[\mathbb{F},\mathcal{L}^k,d/k] RS [ F , L k , d / k ] δ \delta δ 1 − p o l y ( ∣ L ∣ / ∣ F ∣ ) 1 - \mathrm{poly}(|\mathcal{L}|/|\mathbb{F}|) 1 − poly ( ∣ L ∣/∣ F ∣ ) 根据 Out-of-domain Sampling 的性质,g g g 1 − ρ ′ 1 - \sqrt{\rho'} 1 − ρ ′ u ^ \hat{u} u ^ u ^ ( r o u t ) = β \hat{u}(r^{\mathrm{out}}) = \beta u ^ ( r out ) = β 1 − p o l y ( ∣ L ∣ ) / ∣ F ∣ 1 - \mathrm{poly}(|\mathcal{L}|)/|\mathbb{F}| 1 − poly ( ∣ L ∣ ) /∣ F ∣ 现在分析下第 2 点,函数 g : L ′ → F g: \mathcal{L}' \rightarrow \mathbb{F} g : L ′ → F R S [ F , L ′ , d / k ] \mathrm{RS}[\mathbb{F}, \mathcal{L}', d/k] RS [ F , L ′ , d / k ] R S [ F , L ′ , d / k ] \mathrm{RS}[\mathbb{F}, \mathcal{L}', d/k] RS [ F , L ′ , d / k ] ( γ , l ) (\gamma, l) ( γ , l ) γ ≈ 1 − ρ ′ \gamma \approx 1 - \sqrt{\rho'} γ ≈ 1 − ρ ′ l = p o l y ( ∣ L ′ ∣ ) = p o l y ( ∣ L ∣ ) l = \mathrm{poly}(|\mathcal{L}'|) =\mathrm{poly}(|\mathcal{L}|) l = poly ( ∣ L ′ ∣ ) = poly ( ∣ L ∣ ) l l l d / k d/k d / k g g g γ \gamma γ l l l u ^ ′ \hat{u}' u ^ ′ u ^ \hat{u} u ^ F \ L ′ \mathbb{F} \backslash \mathcal{L}' F \ L ′ r o u t r^{\mathrm{out}} r out r o u t r^{\mathrm{out}} r out β \beta β d / k − 1 ∣ F ∣ − ∣ L ′ ∣ \frac{d/k - 1}{|\mathbb{F}| - |\mathcal{L}'|} ∣ F ∣ − ∣ L ′ ∣ d / k − 1 ( l 2 ) \binom{l}{2} ( 2 l )
( l 2 ) ⋅ d / k − 1 ∣ F ∣ − ∣ L ′ ∣ = O ( l 2 ⋅ ( d / k − 1 ) ∣ F ∣ − ∣ L ′ ∣ ) = p o l y ( ∣ L ∣ ) / ∣ F ∣ . \binom{l}{2} \cdot \frac{d/k - 1}{|\mathbb{F}| - |\mathcal{L}'|} = O\left(\frac{l^2 \cdot (d/k - 1)}{|\mathbb{F}| - |\mathcal{L}'|}\right) = \mathrm{poly}(|\mathcal{L}|)/|\mathbb{F}|. ( 2 l ) ⋅ ∣ F ∣ − ∣ L ′ ∣ d / k − 1 = O ( ∣ F ∣ − ∣ L ′ ∣ l 2 ⋅ ( d / k − 1 ) ) = poly ( ∣ L ∣ ) /∣ F ∣. 因此 g g g 1 − ρ ′ 1 - \sqrt{\rho'} 1 − ρ ′ u ^ \hat{u} u ^ u ^ ( r o u t ) = β \hat{u}(r^{\mathrm{out}}) = \beta u ^ ( r out ) = β 1 − p o l y ( ∣ L ∣ ) / ∣ F ∣ 1 - \mathrm{poly}(|\mathcal{L}|)/|\mathbb{F}| 1 − poly ( ∣ L ∣ ) /∣ F ∣
如果第 1 项和第 2 项都成立,那么这个概率超过 1 − p o l y ( ∣ L ∣ ) / ∣ F ∣ 1 - \mathrm{poly}(|\mathcal{L}|)/|\mathbb{F}| 1 − poly ( ∣ L ∣ ) /∣ F ∣ f ′ f' f ′ R S [ F , L ′ , d / k − ∣ G ∣ ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k- |\mathcal{G}|] RS [ F , L ′ , d / k − ∣ G ∣ ] ( 1 − ρ ′ ) (1 - \sqrt{\rho'}) ( 1 − ρ ′ ) 1 − ( 1 − δ ) t 1 - (1 - \delta)^t 1 − ( 1 − δ ) t
下面分两种情况进行讨论:
如果在第 2 项中没有码字满足要求,即在 g g g 1 − ρ ′ 1 - \sqrt{\rho'} 1 − ρ ′ u ^ ( r o u t ) = β \hat{u}(r^{\mathrm{out}}) = \beta u ^ ( r out ) = β p ( r o u t ) = β p(r^{\mathrm{out}}) = \beta p ( r out ) = β g g g 1 − ρ ′ 1 - \sqrt{\rho'} 1 − ρ ′ u ^ ( r o u t ) ≠ p ( r o u t ) \hat{u}(r^{\mathrm{out}}) \neq p(r^{\mathrm{out}}) u ^ ( r out ) = p ( r out )
f ′ : = Q u o t i e n t ( g , G , p ) = g ( x ) − p ^ ( x ) ∏ a ∈ G ( X − a ) . f' := \mathrm{Quotient}(g, \mathcal{G}, p) = \frac{g(x) - \hat{p}(x)}{\prod_{a \in \mathcal{G}}(X - a)}. f ′ := Quotient ( g , G , p ) = ∏ a ∈ G ( X − a ) g ( x ) − p ^ ( x ) . 根据 Quotient 函数的一致性,此时 u ^ \hat{u} u ^ p p p G \mathcal{G} G f ′ = Q u o t i e n t ( f , G , p ) f' = \mathrm{Quotient}(f, \mathcal{G}, p) f ′ = Quotient ( f , G , p ) R S [ F , L ′ , d / k − ∣ G ∣ ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k- |\mathcal{G}|] RS [ F , L ′ , d / k − ∣ G ∣ ] ( 1 − ρ ′ ) (1 - \sqrt{\rho'}) ( 1 − ρ ′ )
如果在第 2 项中存在一个码字 u ^ \hat{u} u ^ g g g 1 − ρ ′ 1 - \sqrt{\rho'} 1 − ρ ′ u ^ ( r o u t ) = β \hat{u}(r^{\mathrm{out}}) = \beta u ^ ( r out ) = β
f ′ : = Q u o t i e n t ( g , G , p ) = g ( x ) − p ^ ( x ) ∏ a ∈ G ( X − a ) . f' := \mathrm{Quotient}(g, \mathcal{G}, p) = \frac{g(x) - \hat{p}(x)}{\prod_{a \in \mathcal{G}}(X - a)}. f ′ := Quotient ( g , G , p ) = ∏ a ∈ G ( X − a ) g ( x ) − p ^ ( x ) . 现在已经满足 u ^ ( r o u t ) = β = p ( r o u t ) \hat{u}(r^{\mathrm{out}}) = \beta = p(r^{\mathrm{out}}) u ^ ( r out ) = β = p ( r out ) i ∈ [ t ] i \in [t] i ∈ [ t ] u ^ ( r i s h i f t ) = y i = p ( r i s h i f t ) \hat{u}(r_i^{\mathrm{shift}}) = y_i = p(r_i^{\mathrm{shift}}) u ^ ( r i shift ) = y i = p ( r i shift ) f ′ = Q u o t i e n t ( f , G , p ) f' = \mathrm{Quotient}(f, \mathcal{G}, p) f ′ = Quotient ( f , G , p ) R S [ F , L ′ , d / k − ∣ G ∣ ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k- |\mathcal{G}|] RS [ F , L ′ , d / k − ∣ G ∣ ] ( 1 − ρ ′ ) (1 - \sqrt{\rho'}) ( 1 − ρ ′ ) i i i u ^ ( r i s h i f t ) ≠ y i \hat{u}(r_i^{\mathrm{shift}}) \neq y_i u ^ ( r i shift ) = y i u ^ ( r i s h i f t ) ≠ p ( r i s h i f t ) \hat{u}(r_i^{\mathrm{shift}}) \neq p(r_i^{\mathrm{shift}}) u ^ ( r i shift ) = p ( r i shift ) f ′ f' f ′ R S [ F , L ′ , d / k − ∣ G ∣ ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k- |\mathcal{G}|] RS [ F , L ′ , d / k − ∣ G ∣ ] ( 1 − ρ ′ ) (1 - \sqrt{\rho'}) ( 1 − ρ ′ )
由于第 1 项成立,因此对于折叠函数有 Δ ( f r f o l d , R S [ F , L k , d / k ] ) ≥ δ \Delta(f_{r^{\mathrm{fold}}}, \mathrm{RS}[\mathbb{F}, \mathcal{L}^k, d/k]) \ge \delta Δ ( f r fold , RS [ F , L k , d / k ]) ≥ δ
Pr [ ∀ i ∈ [ t ] , u ^ ( r i s h i f t ) = y i ] = Pr [ ∀ i ∈ [ t ] , u ^ ( r i s h i f t ) = f r f o l d ( r i s h i f t ) ] ≤ ( 1 − δ ) t . \begin{aligned}
\Pr \left[\forall i \in [t], \hat{u}(r_i^{\mathrm{shift}}) = y_i \right] & = \Pr \left[\forall i \in [t], \hat{u}(r_i^{\mathrm{shift}}) = f_{r^{\mathrm{fold}}}(r_i^{\mathrm{shift}}) \right] \\
& \le (1 - \delta)^t.
\end{aligned} Pr [ ∀ i ∈ [ t ] , u ^ ( r i shift ) = y i ] = Pr [ ∀ i ∈ [ t ] , u ^ ( r i shift ) = f r fold ( r i shift ) ] ≤ ( 1 − δ ) t . 因此 f ′ f' f ′ R S [ F , L ′ , d / k − ∣ G ∣ ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k- |\mathcal{G}|] RS [ F , L ′ , d / k − ∣ G ∣ ] ( 1 − ρ ′ ) (1 - \sqrt{\rho'}) ( 1 − ρ ′ ) 1 − ( 1 − δ ) t 1 - (1 - \delta)^t 1 − ( 1 − δ ) t
至此命题 1 得证。\Box
实际上,协议的 round-by-round soundness error 大概就为 max { p o l y ( ∣ L ∣ ) ∣ F ∣ , ( 1 − δ ) t } \max \{\frac{\mathrm{poly}(|\mathcal{L}|)}{|\mathbb{F}|}, (1 - \delta)^t\} max { ∣ F ∣ poly ( ∣ L ∣ ) , ( 1 − δ ) t }
Degree correction ¶ 现在还剩下一个小问题需要解决,那就是根据 f ′ f' f ′
f ′ : = Q u o t i e n t ( g , G , p ) = g ( x ) − p ^ ( x ) ∏ a ∈ G ( X − a ) . f' := \mathrm{Quotient}(g, \mathcal{G}, p) = \frac{g(x) - \hat{p}(x)}{\prod_{a \in \mathcal{G}}(X - a)}. f ′ := Quotient ( g , G , p ) = ∏ a ∈ G ( X − a ) g ( x ) − p ^ ( x ) . 可以发现,准确来讲,这里是将对 f f f f ′ f' f ′ R S [ F , L ′ , d / k − ∣ G ∣ ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k- |\mathcal{G}|] RS [ F , L ′ , d / k − ∣ G ∣ ] R S [ F , L ′ , d / k ] \mathrm{RS}[\mathbb{F},\mathcal{L}',d/k] RS [ F , L ′ , d / k ]
一般地,不妨假设我们要进行次数校正的函数是 f : L → F f: \mathcal{L} \rightarrow \mathbb{F} f : L → F d d d d ∗ ≥ d d^* \ge d d ∗ ≥ d f ∗ f^* f ∗
如果 f ∈ R S [ F , L , d ] f \in \mathrm{RS}[\mathbb{F},\mathcal{L},d] f ∈ RS [ F , L , d ] f ∗ ∈ R S [ F , L , d ∗ ] f^* \in \mathrm{RS}[\mathbb{F},\mathcal{L},d^*] f ∗ ∈ RS [ F , L , d ∗ ] 如果 f f f R S [ F , L , d ] \mathrm{RS}[\mathbb{F},\mathcal{L},d] RS [ F , L , d ] δ \delta δ f ∗ f^* f ∗ R S [ F , L , d ∗ ] \mathrm{RS}[\mathbb{F},\mathcal{L},d^*] RS [ F , L , d ∗ ] δ \delta δ 对 f ∗ f^* f ∗ f f f STIR 论文 ([ACFY24], 第 2.3 节) 中提出了一种方法,不仅满足上述三个条件,还利用几何级数求和的方法,使得第 3 项的计算更加高效。
该方法是,随机采样一个域中的元素 r ← F r \leftarrow \mathbb{F} r ← F
f ∗ ( x ) = ∑ i = 0 e r i ⋅ f i ( x ) (1) f^*(x) = \sum_{i=0}^{e} r^i \cdot f_i(x) \tag{1} f ∗ ( x ) = i = 0 ∑ e r i ⋅ f i ( x ) ( 1 ) 其中,f i ( x ) : = x i ⋅ f ( x ) f_i(x) := x^i \cdot f(x) f i ( x ) := x i ⋅ f ( x ) e = d ∗ − d e = d^* - d e = d ∗ − d ( 1 ) (1) ( 1 )
f ∗ ( x ) = r 0 ⋅ x 0 ⋅ f ( x ) + r 1 ⋅ x 1 ⋅ f ( x ) + ⋯ + r e ⋅ x e ⋅ f ( x ) (2) f^*(x) = r^0 \cdot x^0 \cdot f(x) + r^1 \cdot x^1 \cdot f(x) + \cdots + r^e \cdot x^e \cdot f(x) \tag{2} f ∗ ( x ) = r 0 ⋅ x 0 ⋅ f ( x ) + r 1 ⋅ x 1 ⋅ f ( x ) + ⋯ + r e ⋅ x e ⋅ f ( x ) ( 2 ) 根据 f ∗ f^* f ∗
对于 δ < min { 1 − ρ , 1 − ( 1 + 1 / d ∗ ) ⋅ ρ } \delta < \min \{ 1 - \sqrt{\rho}, 1 - (1 + 1/d^*) \cdot \rho\} δ < min { 1 − ρ , 1 − ( 1 + 1/ d ∗ ) ⋅ ρ }
接下来分析下第 3 项。通过 ( 2 ) (2) ( 2 ) f ∗ f^* f ∗ x x x f ( x ) f(x) f ( x ) e + 1 e + 1 e + 1 O ( e ) O(e) O ( e ) e = Ω ( d ) e = \Omega(d) e = Ω ( d ) O ( log e ) O(\log e) O ( log e )
f ∗ ( x ) = ∑ i = 0 e r i ⋅ f i ( x ) = ∑ i = 0 e r i ⋅ x i ⋅ f ( x ) = f ( x ) ⋅ ∑ i = 0 e ( r ⋅ x ) i \begin{aligned}
f^*(x) & = \sum_{i=0}^{e} r^i \cdot f_i(x) \\
& = \sum_{i=0}^{e} r^i \cdot x^i \cdot f(x)\\
& = f(x) \cdot \sum_{i=0}^{e} (r \cdot x)^i \\
\end{aligned} f ∗ ( x ) = i = 0 ∑ e r i ⋅ f i ( x ) = i = 0 ∑ e r i ⋅ x i ⋅ f ( x ) = f ( x ) ⋅ i = 0 ∑ e ( r ⋅ x ) i 对 ∑ i = 0 e ( r ⋅ x ) i \sum_{i=0}^{e} (r \cdot x)^i ∑ i = 0 e ( r ⋅ x ) i
f ∗ ( x ) = { f ( x ) ⋅ 1 − ( r ⋅ x ) e + 1 1 − r ⋅ x if r ⋅ x ≠ 1 f ( x ) ⋅ ( e + 1 ) if r ⋅ x = 1 f^*(x) = \begin{cases}
f(x) \cdot \frac{1 - (r \cdot x)^{e+1}}{1 - r \cdot x} & \text{if} \quad r \cdot x \neq 1 \\
f(x) \cdot (e + 1) & \text{if} \quad r \cdot x = 1
\end{cases} f ∗ ( x ) = { f ( x ) ⋅ 1 − r ⋅ x 1 − ( r ⋅ x ) e + 1 f ( x ) ⋅ ( e + 1 ) if r ⋅ x = 1 if r ⋅ x = 1 对于比较复杂的 f ( x ) ⋅ 1 − ( r ⋅ x ) e + 1 1 − r ⋅ x f(x) \cdot \frac{1 - (r \cdot x)^{e+1}}{1 - r \cdot x} f ( x ) ⋅ 1 − r ⋅ x 1 − ( r ⋅ x ) e + 1 ( r ⋅ x ) e + 1 (r \cdot x)^{e+1} ( r ⋅ x ) e + 1 O ( log e ) O(\log e) O ( log e ) f f f x x x f ( x ) f(x) f ( x ) O ( log e ) O(\log e) O ( log e ) f ∗ ( x ) f^*(x) f ∗ ( x )
将该方法可以扩展到多个不同次数的函数上。对于 m m m f 1 , … , f m : L → F f_1, \ldots, f_m: \mathcal{L} \rightarrow \mathbb{F} f 1 , … , f m : L → F d 1 , … , d m d_1, \ldots, d_m d 1 , … , d m f ∗ f^* f ∗ d ∗ d^* d ∗ r ← F r \leftarrow \mathbb{F} r ← F e i = d ∗ − d i e_i = d^* - d_i e i = d ∗ − d i
f ∗ ( x ) = ∑ i = 0 e 1 r i ⋅ x i ⋅ f 1 ( x ) + r 1 + e 1 ∑ i = 0 e 2 r i ⋅ x i ⋅ f 2 ( x ) + ⋯ + r m − 1 + ∑ j = 1 m − 1 e j ∑ i = 0 e m r i ⋅ x i ⋅ f m ( x ) . f^*(x) = \sum_{i = 0}^{e_1} r^i \cdot x^i \cdot f_1(x) + r^{1 + e_1} \sum_{i = 0}^{e_2} r^i \cdot x^i \cdot f_2(x) + \cdots + r^{m - 1 + \sum_{j = 1}^{m - 1}e_j} \sum_{i = 0}^{e_m} r^i \cdot x^i \cdot f_m(x). f ∗ ( x ) = i = 0 ∑ e 1 r i ⋅ x i ⋅ f 1 ( x ) + r 1 + e 1 i = 0 ∑ e 2 r i ⋅ x i ⋅ f 2 ( x ) + ⋯ + r m − 1 + ∑ j = 1 m − 1 e j i = 0 ∑ e m r i ⋅ x i ⋅ f m ( x ) . 与上面单个函数的次数校正类似,对于 δ < min { 1 − ρ , 1 − ( 1 + 1 / d ∗ ) ⋅ ρ } \delta < \min \{ 1 - \sqrt{\rho}, 1 - (1 + 1/d^*) \cdot \rho\} δ < min { 1 − ρ , 1 − ( 1 + 1/ d ∗ ) ⋅ ρ } f i f_i f i R S [ F , L , d i ] \mathrm{RS}[\mathbb{F},\mathcal{L},d_i] RS [ F , L , d i ] δ \delta δ f ∗ f^* f ∗ R S [ F , L , d ∗ ] \mathrm{RS}[\mathbb{F},\mathcal{L},d^*] RS [ F , L , d ∗ ] δ \delta δ f 1 , … , f m f_1, \ldots, f_m f 1 , … , f m O ( ∑ i log e i ) = O ( m ⋅ log d ∗ ) O(\sum_i \log e_i) = O(m \cdot \log d^*) O ( ∑ i log e i ) = O ( m ⋅ log d ∗ ) f ∗ f^* f ∗ x x x
STIR 通过在每一轮中改变函数的 evaluation domain ,将原来 FRI 协议中的 L k \mathcal{L}^k L k L ′ \mathcal{L}' L ′ k k k L ′ \mathcal{L}' L ′
在STIR 协议的构造中使用 RS 编码的几个有力的工具,使得整个协议是高效且安全的。
首先和 FRI 协议一致,先对函数 f f f k k k L k \mathcal{L}^k L k L ′ \mathcal{L}' L ′ 接着为了降低 Verifier 的工作,使用 Out of Domain Sampling 的方式将列表编码的方式转换为唯一解码,也就是协议中 Verifier 从 F \ L \mathbb{F} \backslash \mathcal{L} F \ L r o u t r^{\mathrm{out}} r out β \beta β 此时将 evaluation domain 变为 L ′ \mathcal{L}' L ′ k k k f r f o l d \mathrm{f}_{r^{\mathrm{fold}}} f r fold L k \mathcal{L}^k L k L k \mathcal{L}^k L k L k \mathcal{L}^k L k L k \mathcal{L}^k L k t t t r i s h i f t r_{i}^{\mathrm{shift}} r i shift 最后结合 r o u t r^{\mathrm{out}} r out r i s h i f t r_{i}^{\mathrm{shift}} r i shift 结合这些工具对一次迭代的 STIR 协议进行了 soundness 分析,其实可以得到 STIR 的 round-by-round soundness error 为 max { p o l y ( ∣ L ∣ ) ∣ F ∣ , ( 1 − δ ) t } \max \{\frac{\mathrm{poly}(|\mathcal{L}|)}{|\mathbb{F}|}, (1 - \delta)^t\} max { ∣ F ∣ poly ( ∣ L ∣ ) , ( 1 − δ ) t }
最后为了将迭代后的 f ′ f' f ′ d / k − ∣ G ∣ d/k - |\mathcal{G}| d / k − ∣ G ∣ d / k d/k d / k
References ¶ [ACFY24] Gal Arnon, Alessandro Chiesa, Giacomo Fenzi, and Eylon Yogev. “STIR: Reed-Solomon proximity testing with fewer queries.” In Annual International Cryptology Conference , pp. 380-413. Cham: Springer Nature Switzerland, 2024. [BCIKS20] Eli Ben-Sasson, Dan Carmon, Yuval Ishai, Swastik Kopparty, and Shubhangi Saraf. Proximity Gaps for Reed–Solomon Codes. In Proceedings of the 61st Annual IEEE Symposium on Foundations of Computer Science , pages 900–909, 2020. [BCS16] Eli Ben-Sasson, Alessandro Chiesa, and Nicholas Spooner. “Interactive Oracle Proofs”. In: Proceedings of the 14th Theory of Cryptography Conference . TCC ’16-B. 2016, pp. 31–60. [BGKS20] Eli Ben-Sasson, Lior Goldberg, Swastik Kopparty, and Shubhangi Saraf. “DEEP-FRI: Sampling Outside the Box Improves Soundness”. In: Proceedings of the 11th Innovations in Theoretical Computer Science Conference . ITCS ’20. 2020, 5:1–5:32. STIR: Reed–Solomon Proximity Testing with Fewer Queries Video: ZK11: STIR: Reed–Solomon Proximity Testing with Fewer Queries - Gal Arnon & Giacomo Fenzi